When you’re operating the website, there may be times when you have multiple URLs you wish to keep out of the search results. This article will cover noindex as one of the methods to achieve just that. We’ll also introduce several case studies.
What is noindex?
Noindex refers to an instruction used to communicate your preference to not have search engines index pages (in other words, preventing pages form showing up in search results). When indexing pages, Google finds a URL, crawls it, and then indexes it, as shown in Figure 1 below. A crash course for beginners detailing the workings of Google Search including the indexing process, can be found in the video below.
Source: How Google Search works | A crash course for beginners. Episode 4
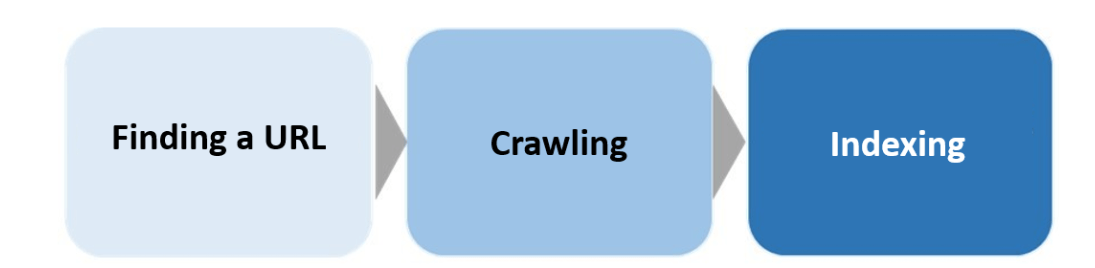
(Figure 1: A simplified view of how Google Search works)
*Content from “How Google Search Works” cited and edited https://www.google.com/intl/
When noindex is used, Google detects the noindex request after executing the crawl so the page isn’t indexed.
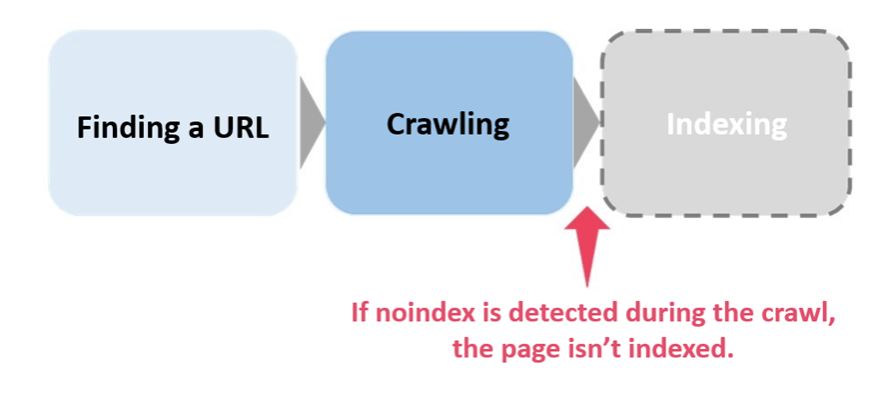
(Figure 2: What happens when noindex is detected)
Difference between noindex and robots.txt
Noindex is often confused with robots.txt. Robots.txt is a request to a search engine that tells it to not crawl. Using it prevents search engines from executing crawls during the indexing process.
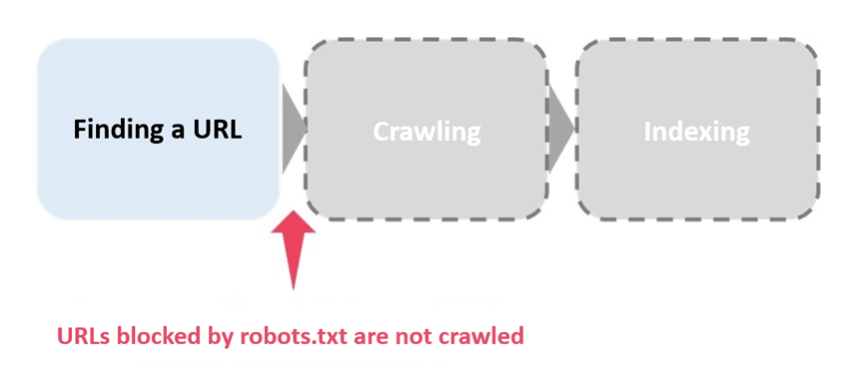
(Figure 3: Blocking URLs with robots.txt)
One point to consider when using robots.txt is that even if a URL is blocked, if the URL is found on an other web page, it may be indexed. Keep in mind that robots.txt is not a means to control indexing, but a method to control crawling.
When to use noindex
The following are instances in which noindex can be used.
– Pages that offer no value to users visiting via search results
Pages that fall under this category include pages with 0 searches within the website, pages with virtually no main content created by the system, and pages with little information. These pages don’t need to be indexed because they offer no value to visitors landing on the page from the search results.
(Figure 4: An example of a web page created by the system with almost no main content)
As for pages that contain information to a certain extent, if the page doesn’t offer value to users visiting from the search results, the search engine may judge the page to be low quality. It’s best to not index these pages because having lots of these pages may affect the rating of the entire website.
– Pages that don’t require traffic from search results
Thank you pages displayed after purchasing a product, web pages displayed while a user is logged in, and other pages whose content depends on the action a user takes don’t assume visits from search results, so there’s no need to index them. Use noindex to prevent such pages from being indexed.
Aside from these cases, you can also use noindex for pages you wish to allow visitors to view but don’t want indexed (displayed in the search results).
How to implement noindex
You can use noindex by using the <meta> tag on the HTTP response header. The majority of people use the <meta> tag. Choose the method that best suits your company’s needs.
- <meta> tag
Include the following description within the <head> section.
| <meta name=”robots” content=”noindex”> |
- HTTP response header
If you won’t be using the <meta> tag, use the HTTP response header. This method can be used for resources other than HTML, including PDFs, video files, and image files. See below for a reference header.
| HTTP/1.1 200 OK (…) X-Robots-Tag: noindex (…) |
How to check noindex
Use the URL Inspection Tool in Google Search Console to check if the search engine has acknowledged the noindex request. If noindex was implemented after the previous crawl, you can request indexing to have the search engine crawl again, reducing the time it takes for noindex to be detected.
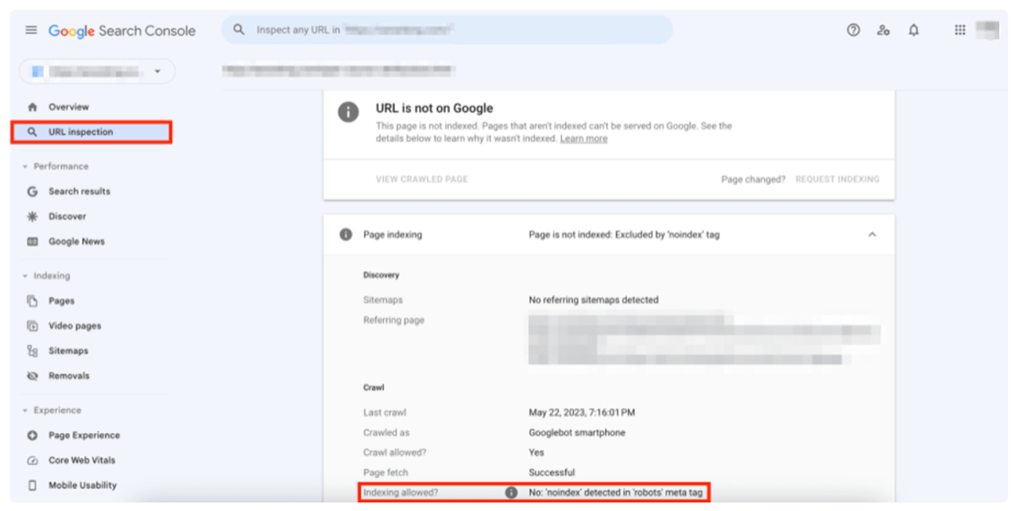
(Figure 5: The results of the URL Inspection Tool showing the detection of noindex)
Summary
This article explored noindex, which can be used to prevent search engines from indexing (displaying on search results) web pages. As always, feel free to contact us if you have any questions on indexing or are facing difficulties.
Want to know more about Digital Marketing?
Contact us to discuss how we can work together.
Irep Inc. is an award-winning global digital marketing agency based in the San Francisco Bay Area. Our headquarters are in Tokyo and our network spans more than 20 countries. In Japan, we are ranked No. 1 for performance-based marketing. We also offer highly specialized market entry, as well as integrated marketing and localization services. Since 1997, our data-driven solutions have effectively led our diverse international clientele to continuous success in Japan, Asia, and beyond.
Irep Inc.
LinkedIn: https://www.linkedin.com/company/irepinc
Email: info@irep.inc
Address: 900 Concar Dr. Suite 400, San Mateo, California 9440